Description of an example Data-Management analysis. C.2008 M Macrae
Requirement:
The company had previously spent something like 2.5 million US Dollars over several years implementing a data-distribution system using SHERPA on a HP-UX workstation. . This had an internal INGRES database to store the descriptions, links, pointers, version data and other details of the hierarchical data files. User requests were queued on the server in demand order and returned to the user system with web-page forms using bin, c, and Unix server-side scripts to transfer files over the network, which spanned several countries via a secure intranet. The system stored obsolete versions of all data.
The requirement was to replace the database and its transactions on the obsolete HP workstation server because the data-management system could not be upgraded to a later version of the Operating system (required by the O/S maintenance contract). The existing 'middleware': data transportation software was to be re-used.
Analysis:
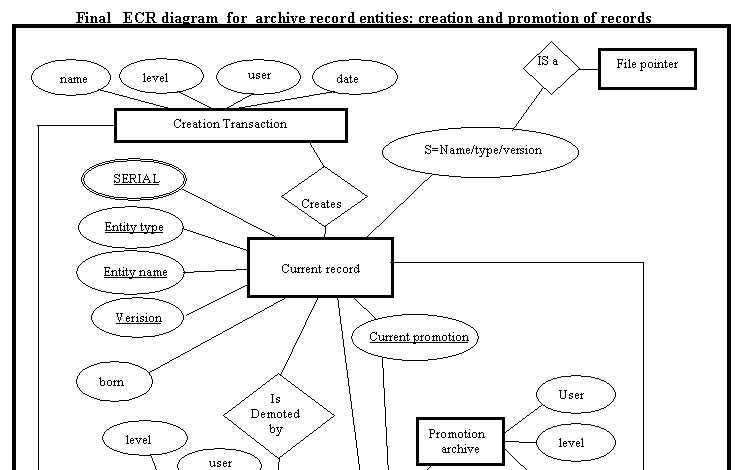
The SHERPA implementation used a complex system to version and instance the data-files and their database pointers, but the date-time had been continually rolled back to allow the server to work with an obsolete license, making date/time reversions difficult. Much of the SHERPA transactions were over-complex. Current and earlier versions of the same data file were held in the same directories. These legacy restrictions made the calculation of hierarchical data collection very difficult. A copy of the LIBRARY number was maintained in the user database copy, and differences were inferred from the LIBRARY number. A finite-set of user transactions was mapped out from interpreting the results of SHERPA transactions. An efficient method of storing data-files was defined.
Design:
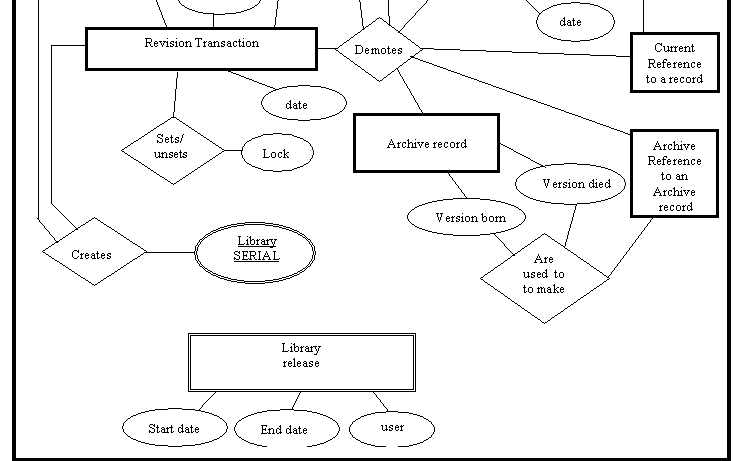
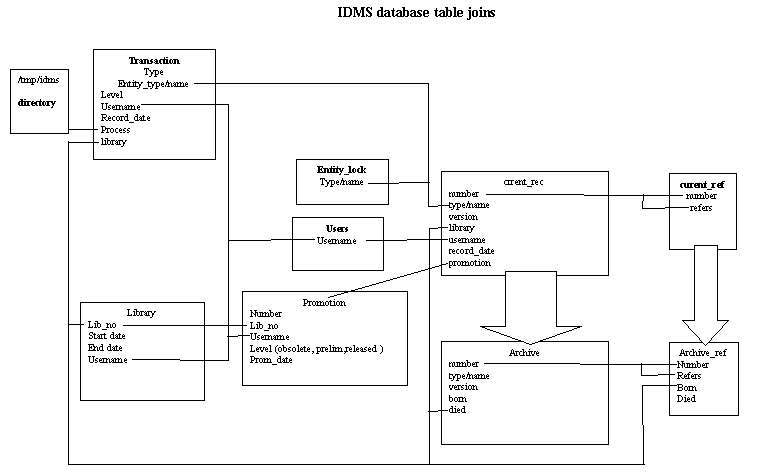
The user network had Informix installed and defined on the user profiles so it was chosen as the data-management system. Rather than copy the existing SHERPA implementation (with its massive inefficiency), a test data-model, transaction set and test data was created to mimic the subset of relevant functions observed as predominant transactions for the system. Current and archive data records were separated into distinct tables and a single function was written in SQL to revert a record/file to archive and add the new record. This was observed as the most important transaction, as it had to complete, even if the network had a transitory failure.
An improved user interface was developed, still using the original asynchronous web forms, but with clearer tables that indicated errors and locked items. A transaction retry timeout system was added to attempt user transactions for a set duration, on the database. Record and file locks were designed so that transactions would exit with meaningful warning messages to the user. Existing hierarchical tree/leaf comparison software was re-used, as was the system to detect internal data changes to linked files.
Implementation:
The test data-model was implemented with a SQL schema. Stored procedures were not available on the installed Informix version, so they were not used. A set of basic functions were built, (e.g.: find record/descendants/ascendants , lock setting/reserving, wait states, absent record warnings etc).Written in KORN Shell script, these functions were combined to make the finite set of user functions called from the User HTML forms. Data-migration scripts to transfer the current records form the SHERPA system were defined.(It was decided that only current records would be transferred from a pre-set date).
Limitations to use.
Some of the existing data-entities distributed by the SHERPA system, were large, and contained other entities themselves (not a complete hierarchical breakdown). The dilemma was the users were familiar with the larger entity keywords, and not the multitude of smaller ones, this limitation was not really solved on the first implementation.
An alternative method for submitting user requests using Java socket connections was tested, to replace the HTML forms with a synchronous client-server application.